
 pytorch
pytorch
# pytorch
# 环境搭建
我的环境:win11+wsl2
- 安装anaconda (opens new window)
- 安装cuda toolkit
- 安装pytorch (opens new window)
注意版本!!
# pytorch加载数据
# dataset类:torch.utils.data.Dataset
# 基本概念
torch.utils.data.Dataset是 PyTorch 中所有数据集类的基类- 它是一个抽象类,需要被继承并实现特定方法
- 用于封装数据和标签,便于训练时使用
# 核心方法
# 1. init 方法
- 初始化数据集
- 通常用于加载文件路径、预处理数据等
# 2. len 方法
- 返回数据集的大小(样本数量)
- 使
len(dataset)成为可能
# 3. getitem 方法
- 支持索引访问,如
dataset[i] - 返回单个数据样本(通常是特征和标签的元组)
示例代码:
import torch
import os
import cv2
from PIL import Image
class MyDataset(torch.utils.data.Dataset):
def __init__(self, root_dir):
self.root_dir = root_dir
self.img_list = os.listdir(root_dir) # 把目录文件内容加载为列表
self.img_list.sort()
self.img_list = [os.path.join(root_dir, img) for img in self.img_list]
# Python 列表推导式
'''
一种简洁、优雅地创建列表的方法。
[expression for item in iterable if condition]
工作原理
遍历:对 iterable(可迭代对象)中的每个 item 进行迭代
条件过滤(可选):如果提供了 if condition,只处理满足条件的项
表达式计算:对每个符合条件的项执行 expression
生成列表:将所有计算结果收集到一个新列表中
'''
def __len__(self):
return len(self.img_list)
def __getitem__(self, idx):
img_path = self.img_list[idx]
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # cv2默认加载BGR格式,RGB为大多数图像处理库和显示器使用
# img = torch.from_numpy(img).permute(2, 0, 1)
return img
ant_dataset = MyDataset("hymenoptera_data/train/ants") # 实例
img = ant_dataset.__getitem__(0) # 获取第一张图片
img = Image.fromarray(img) # cv加载出来的是数组,需要转化一下
img.show()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# TensorBoard的使用
# TensorBoard 简介
# 基本概念
- 可视化工具:用于可视化机器学习实验的各种指标和数据。TensorBoard 是机器学习实验中非常有用的工具,可以帮助更好地理解模型训练过程和调试模型。
- ** originally from TensorFlow**:最初是 TensorFlow 的组件,但现在可以独立使用
- PyTorch 支持:通过
torch.utils.tensorboard模块提供支持
# 主要功能
训练指标可视化:
- 损失函数曲线
- 准确率变化
- 学习率调整
模型结构可视化:
- 神经网络架构图
- 参数分布
数据可视化:
- 图像、音频、文本等
超参数调优:
- 不同实验的对比
- 超参数影响分析
# 使用方法
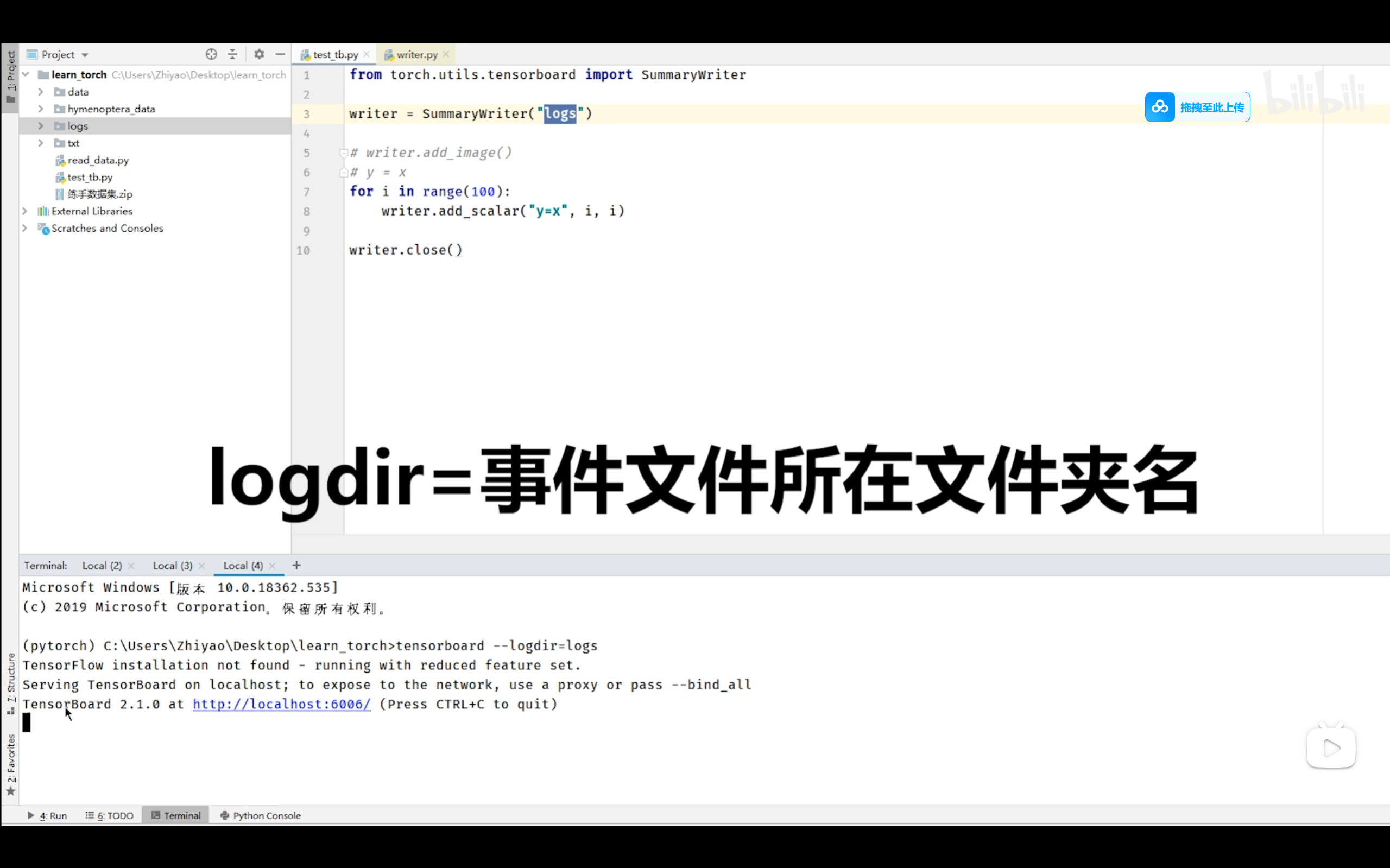
- writer.add_scalar('y=x', i, i) # 绘制图像,arg2为y轴 arg3为x轴
- tensorboard --logdir=logs --port 1001 # logdir指定事件文件所在文件夹名 port指定端口
# Transforms
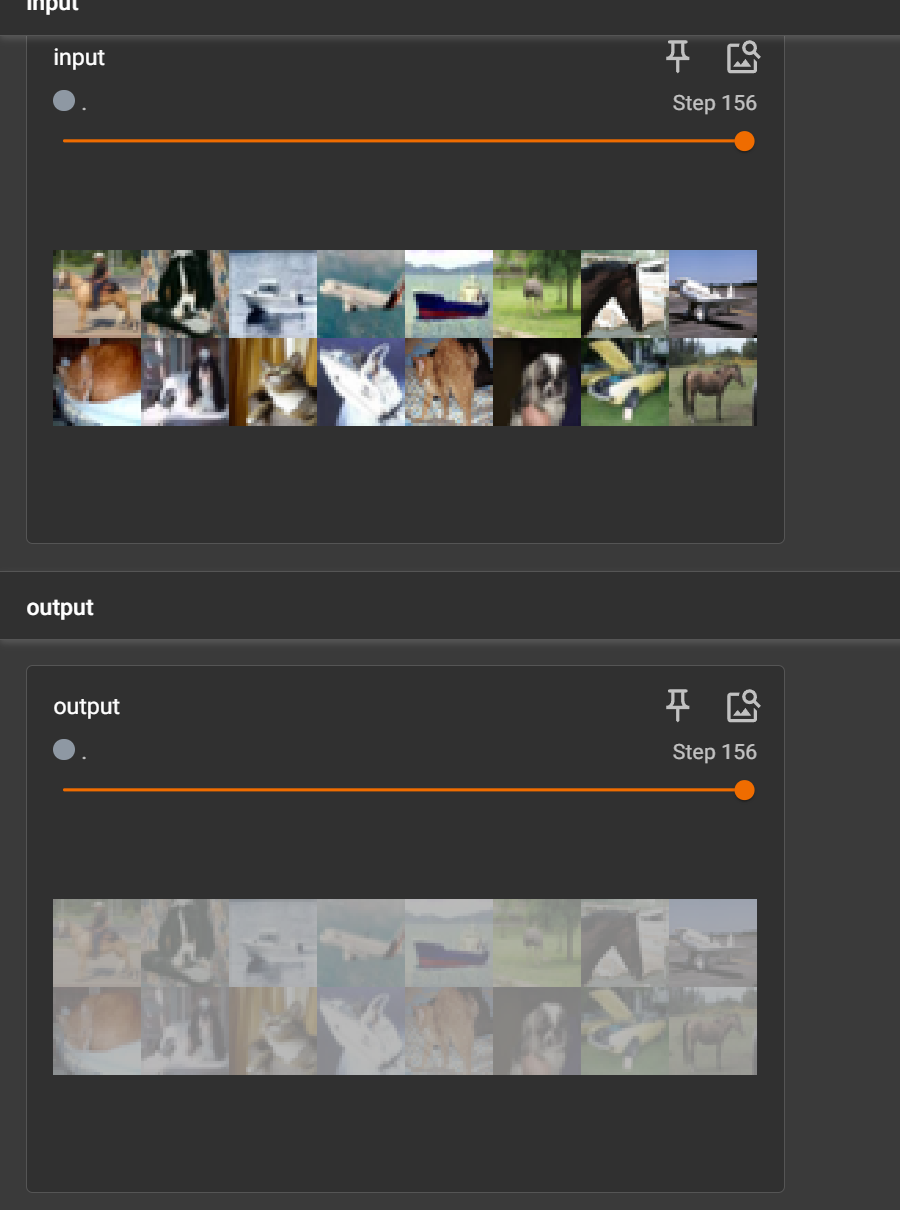
在PyTorch中,transforms 是 torchvision.transforms 模块提供的数据变换工具,主要用于图像和数据预处理。
# 主要功能
- 图像预处理:对输入图像进行各种变换操作
- 数据增强:通过随机变换增加训练数据的多样性
- 数据标准化:将数据转换为模型所需的格式和范围
# 常用的Transforms类型
# 基础变换
ToTensor():将PIL图像或numpy数组转换为tensorNormalize(mean, std):用均值和标准差对张量图像进行标准化Resize(size):调整图像大小CenterCrop(size):中心裁剪图像
# 数据增强变换
RandomHorizontalFlip(p=0.5):随机水平翻转RandomVerticalFlip(p=0.5):随机垂直翻转RandomRotation(degrees):随机旋转RandomCrop(size):随机裁剪
# 组合变换
Compose(transforms):将多个变换组合在一起按顺序执行
# Tensor
两个问题:
transforms如何使用?
- 把图片转化为张量
为什么需要tensor数据类型?
- 方便归一化标准化,继而加速模型收敛
# Normalize
归一化:需要均值和标准差
# Resize
对图像进行resize
# Compose
Compose 将多个变换操作组合成一个单一的变换对象,按顺序依次应用这些变换
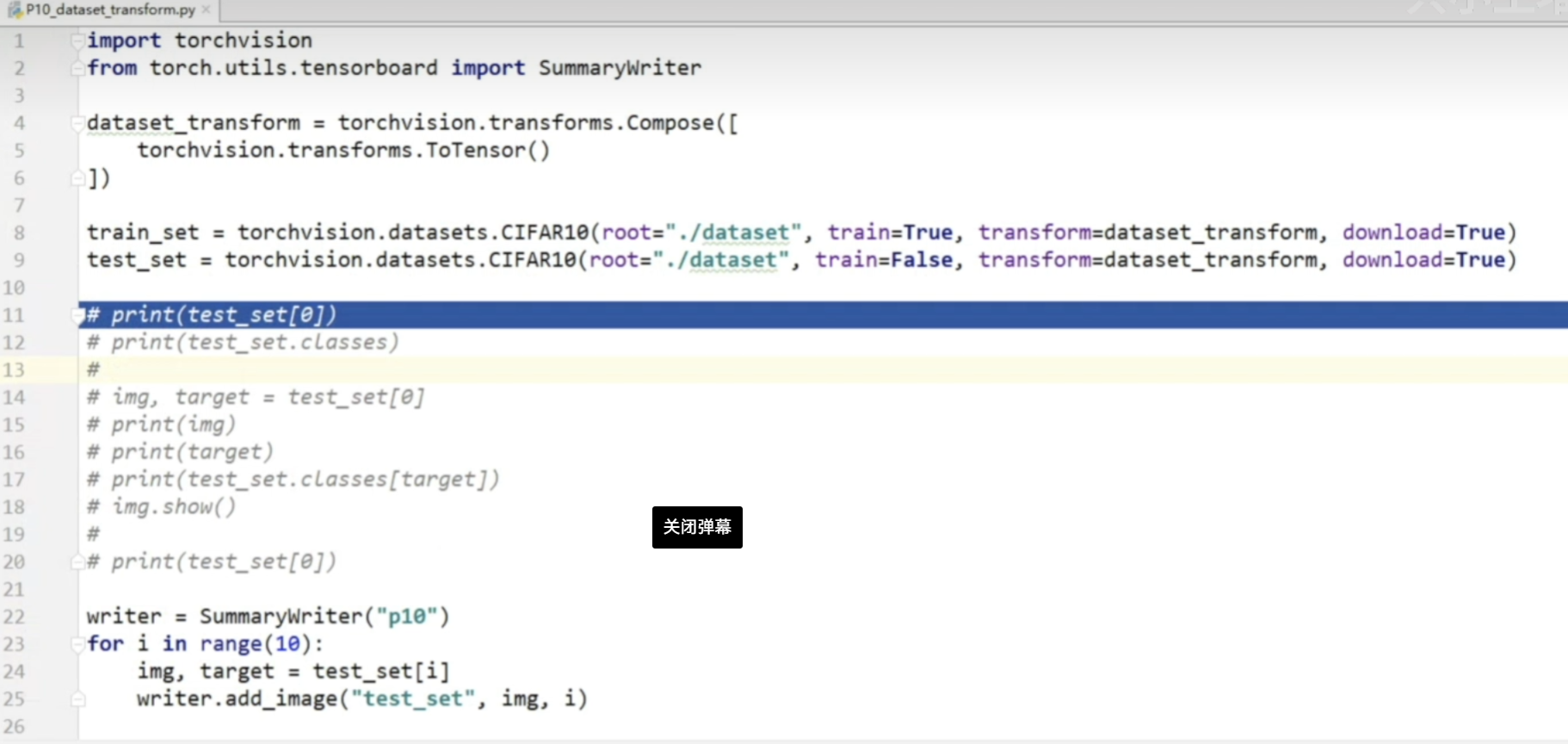
# torchvision数据集使用方法
# Torch.nn
Neural network
# 卷积层
提取特征-卷积核
# 池化层
池化核
为什么需要最大池化?
保留数据特征,减小size,为了训练更快
# 非线性激活层
为什么要用 ReLU?
在神经网络中,我们需要激活函数来让神经元"决定"是否工作:
- 正的输入表示"有信号",让它通过
- 负的输入表示"没信号",把它屏蔽掉(变成0)
这就像是一个简单的"是/否"判断器,帮助神经网络做决策。
Sigmoid现象
# 正则化层
可以加快神经网络训练速度
# 循环神经网络层
主要用于自然语言处理
# transformer层
主要用于转换
# 线性层
# dropout层
随机丢弃一些
主要防止过拟合
# Sequential(序列)
定义模型的时候把各层封装成序列
方便forward处理
# loss函数
1.计算实际输出和目标之间的差距
2.为更新输出提供依据
对loss返回的对象调用backword()方法->反向传播
loss = nn.CrossEntropyLoss()
for data in dataloader:
imgs, targets = data
outputs = _net(imgs)
result = loss(outputs, targets)
result.backward()
1
2
3
4
5
6
2
3
4
5
6
# 优化器
# 如何使用?
- 构造一个优化器:选择优化器算法,放入模型参数,学习速率(lr)->即一次调整的步长
- 调用优化器的step()方法:优化模型的参数,比如卷积核的参数
# pytorch提供的常用网络模型
vgg16:一个现有的网络结构,将输入分为1000个类别,可以在vgg16基础上迁移学习
pretrain_test.py
# 完整的模型训练套路
训练流程
准备数据集
创建网络模型
创建损失函数
创建优化器
训练
测试
# 使用GPU进行训练
# Mode1
对模型,数据,损失函数调用.cuda()
# Mode2
对模型,数据,损失函数调用.to(device)
# 首先定义设备
Device = torch.device("cpu")
torch.device("cuda:0") # 可以指定多个显卡
1
2
3
2
3
上次更新: 2025/11/2 06:53:08