
 GPT
GPT
# GPT
# 概念
全称:生成式预训练Transformer
预训练指的是模型经历了从大量数据中学习的过程,‘预’字暗示模型能针对某些具体任务,通过额外训练来进行微调。
transformer是一种特殊的神经网络,一种机器学习模型,后文会在讲。
CharGPT:输入一段文本,甚至伴随一些图像和音频,预测出文段接下来的内容,并将结果展现为接下来不同文本片段的概率分布
# transfomer数据流
聊天机器人生成特定单词时的流程为例:
输入内容被切成小段,称为token。在文本中token往往是单词或者单词片段;对于图像来说,token则可能表示小块图像或声音片段。每个token对应一个向量,即一组数字:
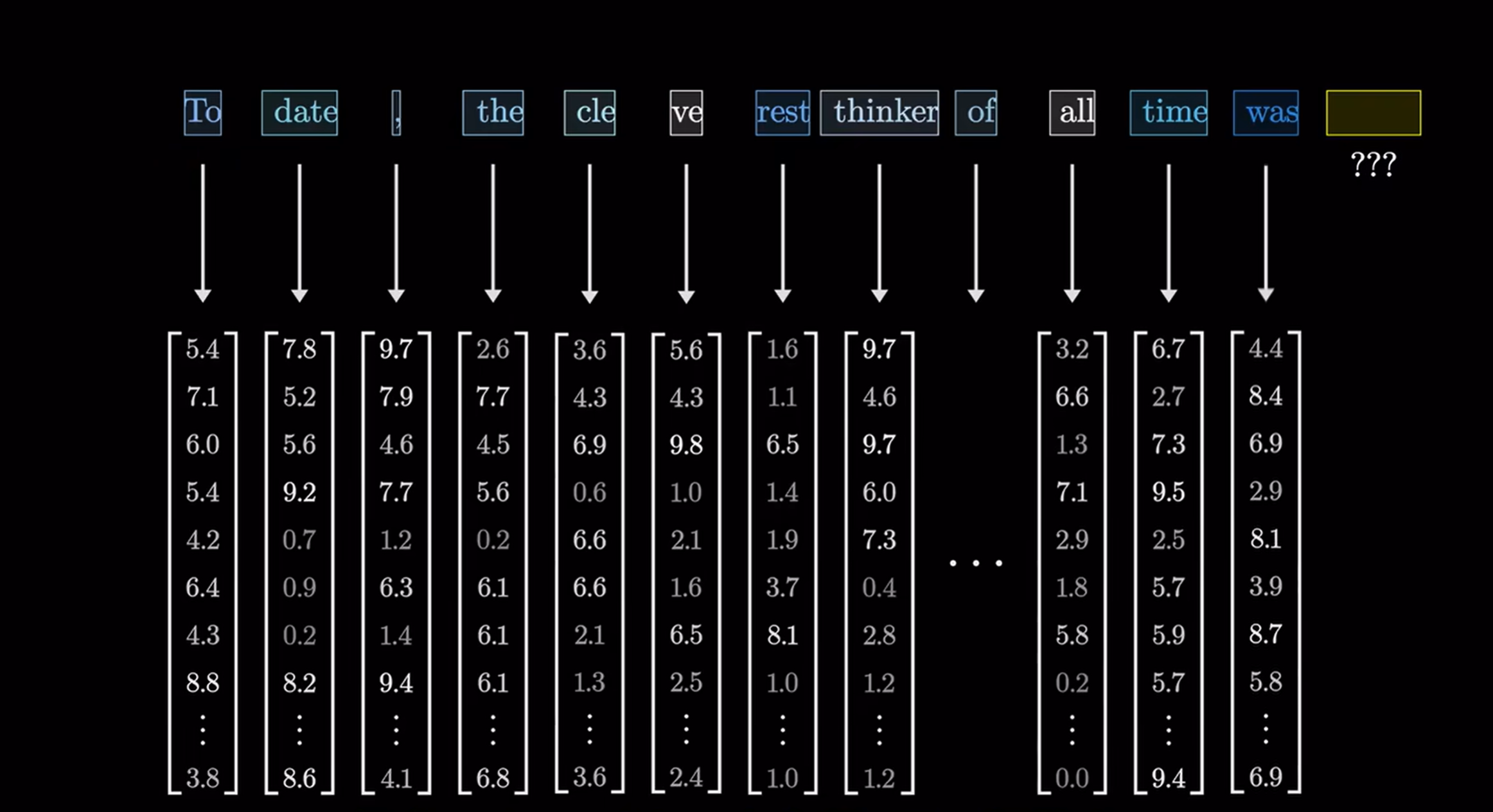
如果把向量看作高维空间的坐标,那么意思相近的词,对应的向量往往也相近。(通过大量训练的结果)
随后经历注意力模块,使得向量之间能够相互交流,通过互相传递信息,来更新自己的值。注意力模块的工作在于 找出上下文中哪些词会改变哪些词的含义,以及这些词应该更新为何种含义。(‘含义’已经通过某种形式完全编码进了这些向量)
之后,向量经过前馈层(也叫MLP:multi-layer perceptron 多层感知器)。在此阶段,向量不再互相交流,而是并行经历同一处理,这一过程大概可以解释为:对每个向量提出一系列问题,然后根据问题的答案来更新向量

上述两个模块的处理,本质都是大量的矩阵乘法。
再之后,基本就是重复这些过程,注意力模块和mlp层层堆叠
下面仍然以聊天机器人为例详细介绍各个层。模型会有一个预设的词汇库,GPT3的数据词汇库里有50257个词。
# 嵌入层
在嵌入矩阵层,每个单词都对应一列向量。暂且记作 $W_e $ ,和其他矩阵一样,初始值是随机的,但将基于数据进行学习。词嵌入往往有很高的维度,即向量长度很高。
相似语义的向量,往往在空间上也比较接近,举个例例子来说比如 “男人” 和 “女人” 之间的向量差就和 “国王” 和 “女王” 之间的向量差很接近。
所以,当你不知道女性君主的词的时候,就可以用 “国王” 一词 加上 “女人” 再减去 “男人” ,然后搜寻他最近的词向量,来找到它。
by the way,训练中发现用空间中的一个方向编码性别信息会更有优势。另一个例子是 如果把意大利加希特勒再减去德国,结果非常靠近墨索里尼的嵌入值(意大利法西斯独裁者)。就好像模型学会了将某个方向与意大利联系起来另一个方向与二战轴心国相关联。
提一个很有用的数学直觉:
两个向量的点积,可以被看做是衡量他们对齐程度的一种方法。从代数角度,点积实际上是将所有对应分量相乘,然后将他们加和。从几何角度,向量的方向相近,则点积为正,相反则负。
GPT-3的token数和维度相乘,权重数约为6.17亿。
# 注意力层
这些token向量能结合上下文语境,比如国王一词,可能被网络中的各个模块逐渐拉扯,最终指向一个更具体细致的方向。该层的目标就是使嵌入层出来的向量能更有效结合上下文信息。即嵌入层出来的向量只有单个单词的语义,通过注意力层,能使这些向量获得比单个词更丰富更具体地含义。
注意力层网络一次只能处理特定数量地向量,称作它的上下文长度。GPT-3的上下文长度为2048。因此,流经此网络的数据有2048列。上下文长度限制了每次预测时能结合的文本量,这就是为什么有些聊天机器人在进行长对话时往往会感觉健忘。
注意力层的细节下节讲。
# 解码层
目标输出时下一个可能token的概率分布。例如如果最后一个词是 “教授” ,而上下文包括 “哈利波特” “最不喜欢的老师”等,那么一个训练良好的网络在积累了哈利波特有关知识后大概率会给 “斯内普” 一词打高分。这涉及了两个步骤:
首先用一个矩阵,将上下文中的最后一个向量,映射到一个包含50000个值的列表,每个值对应词库里的一个token
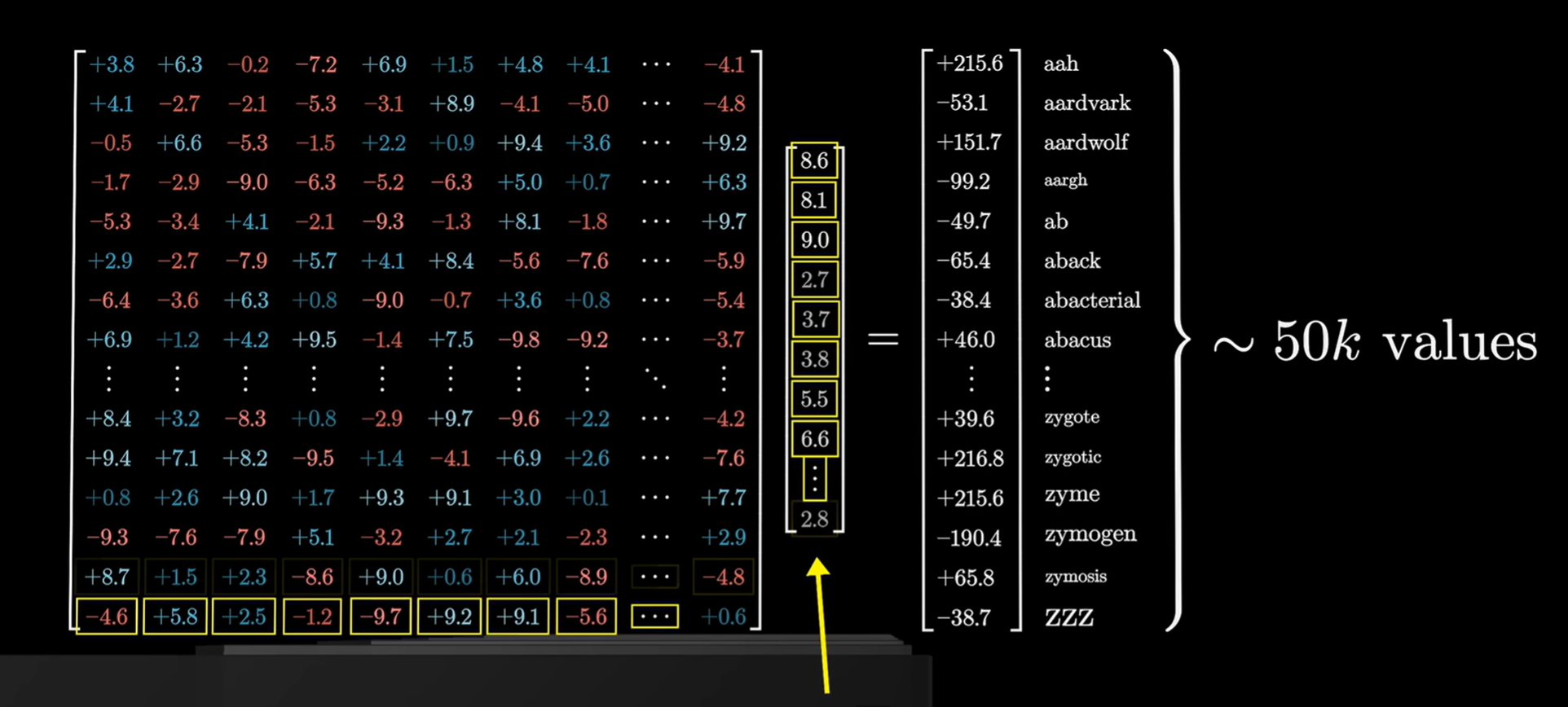
然后一个函数将其归一化为概率分布,即softmax()
映射的方式是通过解嵌入矩阵
(上图左边那个大矩阵,50000行 * 1200列,即词汇数 * 维度)与token向量做点乘,它会在训练中学习,解嵌入矩阵的每行对应词汇库中的一词,每一列对应一个嵌入维度,它与嵌入矩阵很像只不过行列对调。因此这又是6亿个参数.
# softmax函数
基本想法是,若想将一串数字作为概率分布,每一个值必须介于0-1,并且总和为1。 softmax就是将向量值映射到0-1的值。